Substitution and Positioning Rules
- Types of Substitution Rule
- Types of Positioning Rule
- Anchor attachment
- Using hb-shape to check positioning rules
As we have seen, OpenType Layout involves first substituting glyphs to rewrite the input stream, and then positioning glyphs to put them in the right place. We do this by writing collections of rules (called lookups). There are several different types of rule, which instruct the shaper to perform the substitution or positioning in subtly different ways.
In this chapter, we’ll examine each of these types of rule, by taking examples of how they can be used to layout global scripts. In the next chapter, we’ll look at things the other way around - given something we want to do with a script, how can we get OpenType to do it? But to get to that stage, we need to be familiar with the possibilities that we have at our disposal.
Types of Substitution Rule
The simplest type of substitution feature available in the GSUB table is a single, one-to-one substitution: when the feature is turned on, one glyph becomes another glyph. A good example of this is small capitals: when your small capitals feature is turned on, you substitute “A” by “A.sc”, “B” by “B.sc” and so on. Arabic joining is another example: the shaper will automatically turn on the fina feature for the final glyph in a conjoined form, but we need to tell it which substitution to make.
The possible syntaxes for a single substitution are:
sub <glyph> by <glyph>;
substitute <glyphclass> by <glyph>;
substitute <glyphclass> by <glyphclass>;
The first form is the simplest: just change this for that. The second form means “change all members of this glyph class into the given glyph”. The third form means “substitute the corresponding glyph from class B for the one in class A”. So to implement small caps, we could do this:
feature smcp {
substitute [a-z] by [A.sc - Z.sc];
}
To implement Arabic final forms, we would do something like this:
feature fina {
sub uni0622 by uni0622.fina; # Alif madda
sub uni0623 by uni0623.fina; # Alif hamza
sub uni0624 by uni0624.fina; # Waw hamza
...
}
Again, in these particular situations, your font editing software may pick up on glyphs with those “magic” naming conventions and automatically generate the features for you. Single substitutions are simple; let’s move on to the next category.
Multiple substitution
Single substitution was one-to-one. Multiple substitution is one-to-many: it decomposes one glyph into multiple different glyphs. The syntax is pretty similar, but with one thing on the left of the by and many things on the right.
This can be useful if you have situations where composed glyphs with marks are replaced by a decomposition of another glyph and a combining mark. For example, sticking with the Arabic final form idea, if you haven’t designed a specific glyph for alif madda in final form, you can get around it by doing this:
feature fina {
# Alif madda -> final alif + madda above
sub uni0622 by uni0627.fina uni0653;
}
This tells the shaper to split up final alif madda into two glyphs; you have the final form of alif, and so long as your madda mark is correctly positioned, you are essentially synthesizing a new glyph out of the two others.
In fact, when engineering Arabic fonts, it can be extremely useful to separate the dots (nukta) from the base glyphs (rasm). This allows you to reposition the dots independently of the base characters, and it can reduce the number of glyphs that you need to design and write rules for, as you only need to draw and engineer the “skeleton” form for each character.
To do this, you would add empty glyphs to the font so that the Unicode codepoints can be mapped properly, but have the outline provided by other glyphs substituted in the ccmp (glyph composition and decomposition feature). For example, we can provide the glyph ز (zain) by having an empty zain-ar glyph mapped to codepoint U+0632, but in our ccmp feature do this:
feature ccmp {
sub zain-ar by reh-ar dot-above;
} ccmp;
With this rule applied, we now no longer need to deal with zain as a special case - any future rule which applies to reh will deal correctly with the zain situation as well, so you have fewer “letters” to think about.
Alternate substitution
After one-to-many, we have what OpenType calls “one from many”; that is, one glyph can be substituted by one out of a set of glyphs. On the face of it, this doesn’t make much sense - how can the engine choose which “one out of the set” it should substitute? Well, the answer is: it doesn’t. This substitution is designed for features where the shaping engine is expected to pass a set of glyphs to the user interface, so that the user can choose which one they want.
One such feature is aalt, “access all alternates”, which is used by the “glyph palette” window in various pieces of design software. The idea behind this feature is that a user selects a glyph, and the design software asks the shaping engine to return the set of all possible glyphs that the user might want to use instead of that glyph - all the different swash, titling, small capitals or other variants:
feature aalt {
sub A from [A.swash A.ss01 A.ss02 A.ss03 A.sc];
sub B from [B.swash B.ss01 B.ss02 B.ss03 B.sc];
...
}
Again, this is the sort of thing your font editor might do for you automatically (this is why we use computers, after all).
Another use of this substitution comes in mathematics handling. The ssty feature returns a list of alternate glyphs to be used in superscript or subscript circumstances: the first glyph in the set should be for first-level sub/superscripts, and the second glyph for second-level sub/superscripts. (Any other glyphs returned will be ignored, as math typesetting models only recognise two levels of scripting.)
If you peruse the registered feature tags list in the OpenType specification you might find various references to features which should be implemented by GSUB lookup type 3, but the dirty little secret of the OpenType feature tags list is that many of the features are, shall we say… aspirational. They were proposed, accepted, and are now documented in the specification, and frankly they seemed like a really good idea at the time. But nobody ever actually got around to implementing them.
The
randfeature, for example, should perform randomisation, which ought to be an excellent use case for “choose one glyph from a set”. The Harfbuzz shaper has only recently implemented that feature, but we’re still waiting for any application software to request it. Shame, really.
Ligature substitution
We’ve done one to one, and we’ve done one to many - ligature substitution is a many-to-one substitution. You substitute multiple glyphs on the left by the one on the right.
The classic example for Latin script is how the two glyphs “f” and “i” become the single glyph “fi”, but we’ve done that one already. In the Khmer script, when two consonants appear without a vowel between them, the second consonant is written below the first and in a special form. This consonant stack is called a “coeng”, and the convention in Unicode is to encode the stack as CONSONANT 1, U+17D2 KHMER SIGN COENG, CONSONANT 2. (You need the explicit coeng because Khmer is written without word boundaries, and a word-ending consonant followed by a word-beginning consonant shouldn’t trigger a stack.)
So, whenever we see U+17D2 KHMER SIGN COENG followed by a consonant, we should transform this into the special form of the consonant and tuck it below the base consonant.

As you can see from the diagram above, the first consonant doesn’t change; we just need to transform the coeng sign plus the second consonant into the coeng form of that consonant, and then position it appropriately under the first consonant. We know how to muck about with positioning, but for now we need to turn those two glyphs into one glyph. We can use a ligature substitution lookup to do this. We create a rlig (required ligature) feature, which is a ligature that is “required to be used in normal conditions” and “important for some scripts to insure correct glyph formation”, and replace the two glyphs U+17D2 KHMER SIGN COENG plus a consonant, with the coeng forms:
feature rlig {
sub uni17D2 uni1780 by uni1780.coeng;
sub uni17D2 uni1781 by uni1781.coeng;
...
}
In the next chapter, we’ll explore in the next chapter why, instead of ligatures for Arabic rules, you might want to use the following lookup type instead: contextual substitutions.
Chaining Substitutions
The substitutions we’ve seen so far have applied globally - whenever the input glyph matches the rule, the substitution gets made. But what if we want to say that the rule should only apply in certain circumstances?
The next three lookups do just this. They set the context in which a rule applies, and then they specify another lookup or lookups which are invoked at the given positions. The context is made up of what comes before the sequence we want to match (the prefix, or backtrack), the input sequence and lookups, and what comes after the input sequence (the suffix, or lookahead).
Let’s take a couple of examples to explain this concept. We’ll start with a Latin one, taken from the Libertinus fonts. When a Latin capital letter is followed by an accent, then we want to substitute some of those accents by specially designed forms to fit over the capitals:
@capitals = [A B C D E F G H I J K L M N O P Q R S U X Z...];
@accents = [gravecomb acutecomb uni0302 tildecomb ...];
lookup ccmp_cap_accents {
sub acutecomb by acute.cap;
sub gravecomb by grave.cap;
sub uni0302 by circumflex.cap;
sub uni0306 by breve.cap;
} ccmp_cap_accents;
feature ccmp {
sub @capitals @accents' lookup ccmp_cap_accents;
} ccmp;
What this says is: when we see a capital followed by an accent, we’re going to substitute the accent (it’s the replacement sequence, so it gets an apostrophe). But how we do the substitution depends on another lookup we now reference: acute accents for capital acutes, grave accents for capital graves, and so on. The tilde accent does not have a capital form, so is not replaced.
We can also use this trick to perform a many to many substitution, which OpenType does not directly support. In Urdu the yehbarree-ar.fina glyph “goes backwards” with a large negative right sidebearing, and if not handled carefully can bump into glyphs behind it. When threedotsdownbelow-ar occurs before a yehbarre-ar.fina, we want to insert an extender glyph to give a little more room for the dots. Here’s what we want to achieve:
feature rlig {
lookup bari_ye_collision {
sub threedotsdownbelow-ar yehbarree-ar.fina by threedotsdownbelow-ar extender yehbarree-ar.fina;
} bari_ye_collision;
} rlig;
But of course we can’t do this because OpenType doesn’t support many-to-many substitutions. This is where chaining rules come in. To write a chaining rule, first we create a lookup which explains what we want to do:
lookup add_extender_before {
sub yehbarree-ar.fina by extender yehbarree-ar.fina;
} add_extender_before;
Next we create a lookup which explains when we want to do it:
feature rlig {
lookup bari_ye_collision {
sub threedotsdownbelow-ar yehbarree-ar.fina' lookup add_extender_before;
} bari_ye_collision;
} rlig;
Read this as “when a threedotsdownbelow-ar precedes a yehbarree-ar.fina, then call the add_extender_before lookup.” This lookup applies to that yehbarree-ar.fina glyph and replaces it with extender yehbarree-ar.fina, giving the dots a bit more space.
Let’s take another example from the Amiri font, which contains many calligraphic substitutions and special forms. One of these substitutions is that the sequence beh rah (بر) and all similar forms based on the same shape is replaced by another pair of glyphs with a better calligraphic cadence. (Actually, this needs to be done in two cases: when the beh-rah is at the start of the word, and when it is at the end. But we’re going to focus on the one where it is at the end.) How do we do this?
First, we declare our feature and say that we’re not interested in mark glyphs. Then, when we see a beh-like glyph (which includes not only beh, but yeh, noon, beh with three dots, and so on) in its medial form and a rah-like glyph (or jeh, or zain…) in its final form, then both of those glyphs will be subject to a secondary lookup.
@aBaa.medi = [ uni0777.medi uni0680.medi ... ];
@aRaa.fina = [ uni0691.fina uni0692.fina ... ];
feature calt {
lookupflag IgnoreMarks;
sub [@aBaa.medi]' lookup BaaRaaFina
[@aRaa.fina]' lookup BaaRaaFina;
} calt;
The secondary lookup will turn beh-like glyphs into a beh-rah ligature form of beh, and all of the rah-like glyphs into a beh-rah ligature form of rah:
lookup BaaRaaFina {
sub @aBaa.medi by @aBaa.medi_BaaRaaFina;
sub @aRaa.fina by @aRaa.fina_BaaRaaFina;
} BaaRaaFina;
Because this lookup will only be executed when beh and rah appear together, and because it will be executed twice in the rule we gave above, it will change both the beh-like glyph and the rah-like glyph for their contextual calligraphic variants.
Let’s try another example from another script, with a slightly different syntax. Devanagari is an abugida script, where each consonant has an implicit vowel “a” sound. If you want to change that vowel, you precede the consonant with a matra. The “i” matra looks a little bit like the Latin letter f, but its hook is normally designed to stretch across the length of the consonant it follows and “point to” the stem of the consonant. Of course, this gives us a problem: the consonants have differing widths. What we need to do, then, is design a bunch of i-matra glyphs of different widths, and when i-matra is followed by a consonant, substitute it by the variant matra glyph with the appropriate width. For example:
@width1_consonants = [ra-deva rra-deva];
@width2_consonants = [ttha-deva tha-deva];
@width3_consonants = [ka-deva nga-deva ...]
...
feature pres {
lookup imatra {
sub iMatra-deva' @width1_consonants by iMatra-deva.1;
sub iMatra-deva' @width2_consonants by iMatra-deva.2;
sub iMatra-deva' @width3_consonants by iMatra-deva.3;
...
} imatra;
} pres;
Notice that here we are using a syntax which allows us to define both the “what we want to do” lookup (the substitution) and the “when we want to do it” lookup in the same line. The feature compiler will implicitly convert what we have written to:
lookup i1 { sub iMatra-deva' by iMatra-deva.1 } i1;
lookup i2 { sub iMatra-deva' by iMatra-deva.2 } i2;
lookup i3 { sub iMatra-deva' by iMatra-deva.3 } i3;
feature pres {
lookup imatra {
sub iMatra-deva' lookup i1 @width1_consonants;
sub iMatra-deva' lookup i2 @width2_consonants;
sub iMatra-deva' lookup i3 @width3_consonants;
...
} imatra;
} pres;
Again I would encourage you to use the more explicit syntax yourself in all but the simplest of cases to avoid surprises.
We put this in the pres (pre-base substitution) feature, which is designed for substituting pre-base vowels with their conjunct forms, and is normally turned on by shapers when handling Devanagari. The following figure shows the effect of the feature above:

In some cases, you may want to forego a substitution or set of substitutions in particular contexts. For example, in Malayalam, the sequence ka, virama, sa) should appear as a stacked Akhand character “Kssa” - except if the sa is followed by certain vowel sounds which change the form of the sa.
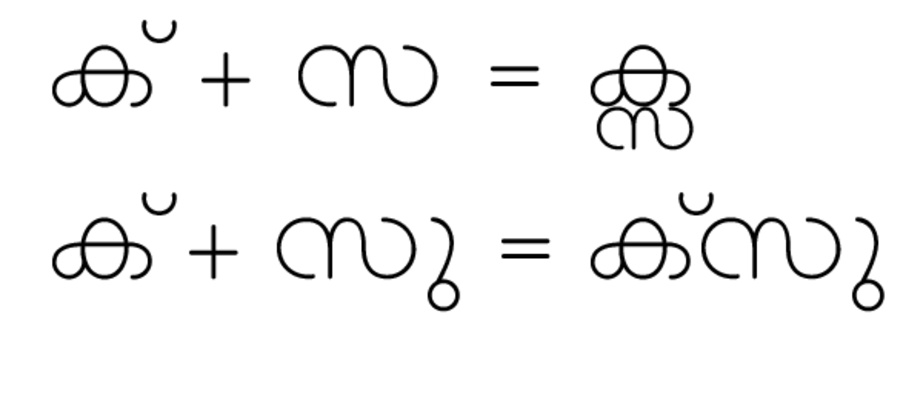
We’ll achieve this in two steps. First, we’ll put a contextual rule in the akhn feature to make the Kssa conjunct. Even though this is a simple substitution we need to write it in the contextual form (using apostrophes, but with an empty backtrack and empty lookahead):
feature akhn {
sub ka-malayalam' halant-malayalam' sa-malayalam' by kssa;
}
This creates the kssa akhand form. Now we need another rule to say “but if you see ka, virama, sa and then a matra, don’t do that substitution.” To do this, we use the ignore keyword:
@matras = [uMatra-malayalam uuMatra-malayalam ...];
feature akhn {
ignore sub ka-malayalam' halant-malayalam' sa-malayalam' @matras;
sub ka-malayalam' halant-malayalam' sa-malayalam' by kssa;
}
This ignore rule ends processing of the current lookup if the context matches. You can have multiple ignore rules: once one of them is matched, processing of the current lookup is terminated. For instance, we also want to forego the akhand form in the sequence “ksra” (because we’re going to want to use the “sra” ligature in that sequence instead):
feature akhn {
ignore sub ka-malayalam' halant-malayalam' sa-malayalam' @matras;
ignore sub ka-malayalam' halant-malayalam' sa-malayalam' halant-malayalam' 'ra-malayalam;
sub ka-malayalam' halant-malayalam' sa-malayalam' by kssa;
}
We said that ignore only terminates processing of a lookup. If you only want to skip over a given number of rules, but consider later rules in the same feature, you need to isolate the relevant ignore/sub rules inside their own lookup:
feature akhn {
lookup Ksa {
ignore sub ka-malayalam' halant-malayalam' sa-malayalam' @matras;
ignore sub ka-malayalam' halant-malayalam' sa-malayalam' halant-malayalam' 'ra-malayalam;
sub ka-malayalam' halant-malayalam' sa-malayalam' by kssa;
# "ksra" is ignored here.
}
# But could be matched here.
}
We can combine contextual substitutions with lookup flags for situations when we want the context to only be interested in certain kinds of glyph. For example, the Arabic font Amiri has an optional stylistic feature whereby if the letter beh follows a waw or rah (for example, in the word ربن - the name “Rabban”, or the word “ribbon” in Urdu) then the nukta on the beh is dropped down:

By now we know how to achieve this:
feature ss01 {
sub @RaaWaw @aBaaDotBelow' by @aBaaLowDotBelow;
} ss01;
The problem is that the text might be vocalised. We still want this rule to apply even if, for example, there is a fatah placed above the rah (رَبَن). We could, of course, attempt to write a context which would apply to rah and waw plus marks all possible combinations of the mark characters, but the easier solution is to tell the shaper that we are not interested in mark characters when applying this rule, only base characters - another use for lookup flags.
feature ss01 {
lookupflag IgnoreMarks;
sub @RaaWaw @aBaaDotBelow' by @aBaaLowDotBelow;
} ss01;
Extension Substitution
An extension substitution (“GSUB lookup type 7”) isn’t really a different kind of substitution so much as a different place to put your substitutions. If you have a very large number of rules in your font, the GSUB table will run out of space to store them. (Technically, it stores the offset to each lookup in a 16 bit field, so there can be a maximum of 65535 bytes from the lookup table to the lookup data. If previous lookups are too big, you can overflow the offset field.)
Most of the time you don’t need to care about this: your font editor may automatically use extension lookups; in some cases, the feature file compiler will rearrange lookups to use extensions when it determines they are necessary; or it may not support extension lookups at all. But if you are getting errors and your font is not compiling because it’s running out of space in the GSUB or GPOS table, you can try adding the keyword useExtension to your largest lookups:
lookup EXTENDED_KERNING useExtension {
# Large number of kerning rules follow
} EXTENDED_KERNING;
Kerning tables are obviously an example of very large positioning lookups, but they’re the most common use of extensions. If you ever get into a situation where you’re procedurally generating rules in a loop from a scripting language, you might end up with a substitution lookup that’s so big it needs to use an extension. As mention in the previous chapter
fonttools feaLibwill reorganise rules into extensions automatically for you, whereasmakeotfwill require you to place things into extensions manually - another reason to preferfonttools.
Reverse chained contextual substitution
The final substitution type is designed for Nastaliq style Arabic fonts (often used in Urdu and Persian typesetting). In that style, even though the input text is processed in right-to-left order, the calligraphic shape of the word is built up in left-to-right order: the form of each glyph is determined by the glyph which precedes it in the input order but follows it in the writing order.
So reverse chained contextual substitution is a substitution that is applied by the shaper backwards in time: it starts at the end of the input stream, and works backwards, and the reason this is so powerful is because it allows you to contextually condition the “current” lookup based on the results from “future” lookups.
As an example, try to work out how you would convert all the numerator digits in a fraction into their numerator form. Tal Leming suggests doing something like this:
lookup Numerator1 {
sub @figures' fraction by @figuresNumerator;
} Numerator1;
lookup Numerator2 {
sub @figures' @figuresNumerator fraction by @figuresNumerator;
} Numerator2;
lookup Numerator3 {
sub @figures' @figuresNumerator @figuresNumerator fraction by @figuresNumerator;
} Numerator3;
lookup Numerator4 {
sub @figures' @figuresNumerator @figuresNumerator @figuresNumerator fraction by @figuresNumerator;
} Numerator4;
# ...
But this is obviously limited: the number of digits processed will be equal to the number of rules you write. To write it for any number of digits, you have to think about the problem in reverse. Start thinking not from the position of the first digit, but from the position of the last digit and work backwards. If a digit appears just before a slash, it gets converted to its numerator form. If a digit appears just before a digit which has already been converted to numerator form, this digit also gets turned into numerator form. Applying these two rules in a reverse substitution chain gives us:
rsub @figures' fraction by @figuresNumerator;
rsub @figures' @figuresNumerator by @figuresNumerator;
Notice that although the lookups are processed with the input stream in reverse order, they are still written with the input stream in normal order of appearance.
XXX Nastaliq
Types of Positioning Rule
After all the substitution rules have been processed, we should have the correct sequence of glyphs that we want to lay out. The next job is to run through the lookups in the GPOS table in the same way, to adjust the positioning of glyphs. We have seen example of single and pair positioning rules. We will see in this section that a number of other ways to reposition glyphs are possible.
To be fair, most of these will be generated more easily and effectively by the user interface of your font editor - but not all of them. Let’s dive in.
Single adjustment
A single adjustment rule just repositions a glyph or glyph class, without contextual reference to anything around it. In Japanese text, all glyphs normally fit into a standard em width and height. However, sometimes you might want to use half-width glyphs, particularly in the case of Japanese comma and Japanese full stop. Rather than designing a new glyph just to change the width, we can use a positioning adjustment:
feature halt {
pos uni3001 <-250 0 -500 0>;
pos uni3002 <-250 0 -500 0>;
} halt;
Remember that this adjusts the placement (placing the comma and full stop) 250 units to the left of where it would normally appear and also the advance, placing the following character 500 units to the left of where it would normally appear: in other words we have shaved 250 units off both the left and right sidebearings of these glyphs when the halt (half-width alternates) feature is selected.
Pair adjustment
We’ve already seen pair adjustment rules: they’re called kerns. They take two glyphs or glyphclasses, and move glyphs around. We’ve also seen that there are two ways to express a pair adjustment rule. First, you place the value record after the two glyphs/glyph classes, and this adjusts the spacing between them.
pos A B -50;
Or you can put a value record after each glyph, which tells you how each of them should be repositioned:
pos @longdescenders 0 uni0956 <0 -90 0 0>;
Cursive attachment
One theme of this book so far has been the fact that digital font technology is based on the “Gutenberg model” of connecting rectangular boxes together on a flat baseline, and we have to work around this model to accomodate scripts which don’t work in that way.
Cursive attachment is one way that this is achieved. If a script is to appear connected, with adjacent glyphs visually joining onto each other, there is an easy way to achieve this: just ensure that every single glyph has an entry stroke and an exit stroke in the same place. In a sense, we did this with the “headline” for our Bengali metrics in chapter 2. Indeed, you will see some script-style fonts implemented in this way:
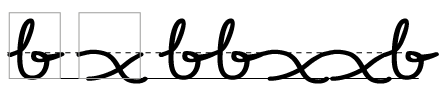
But having each glyph have the same entry and exit profile can look unnatural and forced, especially as you have to ensure that the curves don’t just have the same height but have the same curvature at each entry and exit point. (Noto Naskh Arabic somehow manages to make it work.)
A more natural way to do it, particularly for Nastaliq style fonts, is to tell OpenType where the entry and exit points of your glyph are, and have it sew them together. Consider these three glyphs: two medial lams and an initial gaf.

(Outlines from Noto Nastaliq Urdu)
As they are, they all sit on the same baseline and don’t connect up at all. Now we will add entry and exit anchors in our font editing software, and watch what happens.
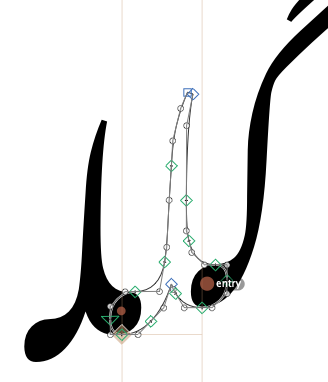
Our flat baseline is no longer flat any more! The shaper has connected the exit anchor of the gaf to the entry anchor of the first lam, and the exit anchor of the first lam to the entry anchor of the second lam. This is cursive attachment.
Glyphs has done this semi-magically for us, but here is what is going on underneath. Cursive attachment is turned on using the curs feature, which is on by default for Arabic script. Inside the curs feature are a number of cursive attachment positioning rules, which define where the entry and exit anchors are:
feature curs {
lookupflag RightToLeft IgnoreMarks;
position cursive lam.medi <anchor 643 386> <anchor -6 180>;
position cursive gaf.init <anchor NULL> <anchor 35 180>;
} curs;
(The initial forms have a NULL entry anchor, and of course final forms will have a NULL exit anchor.) The shaper is responsible for overlaying the anchors to make the exit point and its adjacent entry point fit together. In this case, the leftmost glyph (logically, the last character to be entered) is positioned on the baseline; this is the effect of the lookupflag RightToLeft statement. Without that, the rightmost glyph (first character) would be positioned on the baseline.
Anchor attachment
XXX
Mark positioning
Anchors can also be used to position “mark” glyphs (such as accents) above “base” glyphs. The anusvara (nasalisation) mark in Devanagari is usually placed above a consonant, but where exactly does it go? It often goes above the descending stroke - but not always:

Again, your font editor will usually help you to create the anchors which make this work, but let’s see what is going on underneath. (We’re looking at the Hind font from Indian Type Foundry.)
According to Microsoft’s Devanagari script guidelines, we should use the abvm feature for positioning the anusvara. First, we declare an anchor on the anusvara mark. We do this by asking for a mark class (even though there’s only one glyph in this class), called @MC_abvm.bindu.
markClass dvAnusvara <anchor -94 642> @MC_abvm.bindu;
This specifies a point (with coordinates -94,642) on the dvAnusvara glyph which we will use for attachment.
Next, in our abvm feature, we will declare how this mark is attached to the base glyphs, using the pos base (or position base) command: pos base *baseGlyph* anchor mark *markclass*
feature abvm {
pos base dvAA <anchor 704 642> mark @MC_abvm.bindu;
pos base dvAI <anchor 592 642> mark @MC_abvm.bindu;
pos base dvB_DA <anchor 836 642> mark @MC_abvm.bindu;
#...
} abvm;
This says “you can attach any marks in the class MV_abvm.bindu to the glyph dvAA at position 704,642; on glyph dvAI, they should be attached at position 592,642” and so on.
Mark-to-ligature
This next positioning lookup type deals with how ligature substitutions and marks inter-relate. Suppose we have ligated two Thai characters: NO NU (น) and TO TAO (ต) using a ligature substitution rule:
lookupflag IgnoreMarks;
sub uni0E19' uni0E15' by uni0E190E15.liga;
We’ve ignored any marks here to make the ligature work - but what if there were marks? If the input text had a tone mark over the NO NU (น้), how should that be positioned relative to the ligature? We’ve taken the NO NU away, so now we have uni0E190E15.liga and a tone mark that needs positioning. How do we even know which side of the ligature to attach the mark to - does it go on the NO NU part of the TO TAO part?
Mark-to-ligature positioning helps to solve this problem. It allows us to define anchors on the ligature which represent where to put anchors for each component part. Here is how we do it:
feature mark {
position ligature uni0E190E15.liga # Declare positioning for ligature:
# First component: NO NU
<anchor 325 1400> mark @TOP_MARKS # Anchors for first component
ligcomponent # Component separator
# Second component: TO TAO
<anchor 825 1450> mark @TOP_MARKS # Anchors for second component
;
} mark;
So we write position ligature and the name of the ligated glyph or glyph class, and then, for each component which made up the ligature substitution,
we give one or more mark-to-base positioning rules; then we separate each component by the keyword ligcomponent.
The result is a set of anchors that can be used to attach marks to the appropriate part of ligated glyphs:
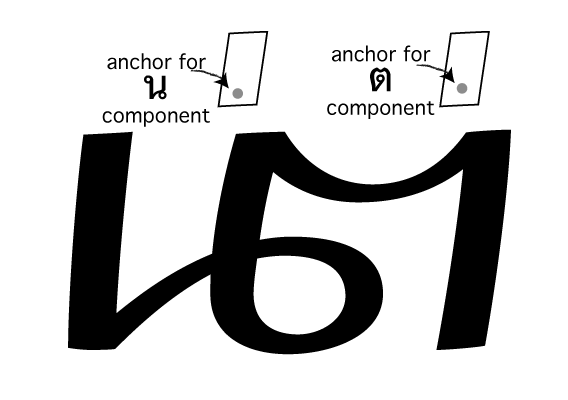
Mark-to-mark
The third kind of mark positioning, mark-to-mark, does what its name implies - it allows marks to have other marks attached to them.
In Arabic, an alif can have a hamza mark attached to it, and can in turn have a damma attached to the hamza. We position this by defining a mark class for the damma as normal:
markClass damma <anchor 189 -103> @dammaMark;
And then we specify, in the mkmk (mark-to-mark) feature, how to attach the hamza to the damma:
feature mkmk {
position mark hamza <anchor 221 301> mark @dammaMark;
} mkmk;
The result: أُ
Once again, this is the kind of feature that is often automatically generated by defining anchors in your font editor.
Contextual and chaining contextual positioning
These two lookup types operate in exactly the same way as their substitution cousins, except with the use of the pos command instead of sub. You provide (optional) backtrack, input marked with apostrophe, and (optional) lookahead as usual.
In a contextual positioning rule, your intersperse the input glyphs with value records. For example, you can create not just kern pairs but kern triplets (or more):
position @number' -25 colon' -25 @number';
This rule reduces the space around a colon when it is surrounded by numbers.
As with a chained contextual substitution rule, in a chained contextual positioning rule, you can intersperse the input glyphs with other positioning lookups. This is where things get very clever. Let’s take an example from the Amiri font. Suppose we have the sequence lam, beh, yeh barree (لبے). Amiri wants to wrap the yeh barree underneath the glyph sequence and to move the nukta of the beh out of the way for a more calligraphic feel.
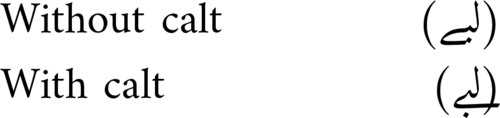
It does this with a chained contextual substitution:
lookup ToothYaaBariFina {
sub @aBaa.medi by @aBaa.medi_YaaBari; # Dropped nukta
...
sub @aYaaBari.fina by @aYaaBari.fina_PostToothFina; # Wrapped yeh
} ToothYaaBariFina;
feature calt {
...
sub [@aBaa.medi]' lookup ToothYaaBariFina
[@aYaaBari.fina]' lookup ToothYaaBariFina;
}
This almost works. The problem is that the barree of the yeh is now sticking out too far to the right for a narrow glyph like lam, and poking its nose into the words to the right of it. What we need to do is add some advance width to the lam in this particular situation. Let’s reword that: if we have a narrow initial letter, followed by a beh in yeh-barree form, then we need to adjust the advance width of the initial letter. But we can’t say exactly how much we need to adjust it by at this stage, because it depends on what the initial letter is; so we need to turn that into a lookup.
We can translate that description above into feature code. First, we set up the context for the positioning lookup:
@narrowInit = [@aAyn.init @aFaa.init @aHeh.init @aLam.init @aMem.init @aSen.init @aTaa.init uni06BE.init]
feature kern {
pos @narrowInit' lookup AvoidYehBaree @aBaa.medi_YaaBari;
}
Next we write a lookup which adjusts the advance width of each of the “narrow” initial characters appropriately to stop the yeh baree poking out:
lookup AvoidYehBaree {
pos @aAyn.init <0 0 215 0>;
...
pos @aLam.init <0 0 466 0>;
...
} AvoidYehBaree;
And here’s the result of those two features - the contextual alternate, and the kerning feature - working together:

That, thankfully, is probably as complicated as it’s going to get.
Using hb-shape to check positioning rules
In the previous chapter we introduced the Harfbuzz utility hb-shape, which is used for debugging the application of OpenType rules in the shaper. As well as looking at the glyphs in the output stream and seeing their advance widths, hb-shape also helps us to know how these glyphs have been repositioned in the Y dimension too.
For example, suppose we are using a mark-to-base feature to position a virama on the Devanagari letter CHA:
markClass @mGC_blwm.virama_n172_0 <anchor -172 0> @MC_blwm.virama;
pos base dvCHA <anchor 276 57> mark @MC_blwm.virama;
What this says is “the attachment point for the virama is at coordinate (-172,0); on the letter CHA, we should arrange things so that attachment point falls at coordinate (276,57).” Where does the virama end up? hb-shape can tell us:
$ hb-shape build/Hind-Regular.otf 'छ्'
[dvCHA=0+631|dvVirama=0@-183,57+0]
So we have a CHA character which is 631 units wide. Next we have a virama which is zero units wide! But when it is drawn, its position is moved - that’s what the “@-183,57” component means: we’ve finished drawing the CHA, and then we move the “pen” negative 183 units in the X direction (183 units to the left) and up 57 units before drawing the virama.
Why is it 183 units? First, let’s see what would happen without the mark-to-base positioning. We can do this by asking hb-shape to turn off the blwm feature when processing:
$ hb-shape --features='-blwm' Hind-Regular.otf 'छ्'
[dvCHA=0+631|dvVirama=0+0]
As you can see, no special positioning has been done. Another utility, hb-view can render the glyphs with the feature set we ask for. If we ask to turn off the blwm feature and see what the result is like, this is what we get:
$ hb-view --features='-blwm' Hind-Regular.otf 'छ्' -O png > test.png
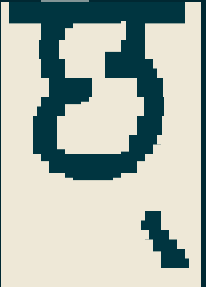
You can also make
hb-viewoutput PNG files, PDFs, and other file formats, which is useful for higher resolution testing. (Look athb-view --help-outputfor more options.) But the old-school ANSI block graphics is quite cute, and shows what we need in this case.
Obviously, this is badly positioned (that’s why we have the blwm feature). What needs to happen to make it right?
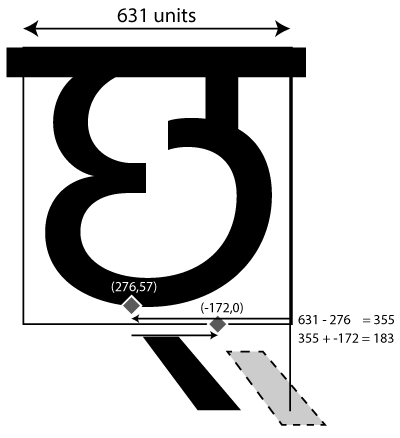
As you can see, the glyph is 631 units wide (Harfbuzz told us that), so we need to go back 355 units to get to the CHA’s anchor position. The virama’s anchor is 172 units to the left of that, so in total we end up going back 183 units. We also raise the glyph up 57 units from its default position.
This example was one which we could probably have tested and debugged from inside our font editor. But as our features become more complex, hb-shape and hb-view become more and more useful for understanding what the shaper is doing with our font files.