OpenType for Global Scripts
- Features in Practice
- Language-specific substitutes
- The letter “i”
- Arabic, Urdu and Sindhi
- Other complex scripts
- The Universal Shaping Engine
- Resources
In the last chapter, we looked at OpenType features from the perspective of technology: what cool things can we make the font do? In this chapter, however, we’re going to look from the perspective of language: how do we make the font support the kind of language features we need? We’ll be putting together the substitution and positioning lookups from OpenType Layout that we learnt about in the previous chapter, and using them to create fonts which behave correctly and beautifully for the needs of different scripts and language systems.
Features in Practice
Up to this point, I have very confidently told you which features you need to use to achieve certain goals - for example, I said things like “We’ll put a contextual rule in the akhn feature to make the Kssa conjunct.” But when it comes to creating your own fonts, you’re going to have to make decisions yourself about where to place your rules and lookups and what features you need to implement. Obviously a good guideline is to look around and copy what other people have done; the growing number of libre fonts on GitHub make it a very helpful source of examples for those learning to program fonts.
But while copying others is a good way to get started, it’s also helpful to reason for oneself about what your font ought to do. There are two parts to being able to do this. The first is a general understanding of the OpenType Layout process and how the shaper operates, and by now you should have some awareness of this. The second is a careful look at the feature tags list of the OpenType specification to see if any of them seem to fit what we’re doing.
Don’t get too stressed out about choosing the right feature for your rules. If you put the rule in a strange feature but your font behaves in the way that you want it to, that’s good enough; there is no OpenType Police who will tell you off for violating the specification. Heck, you can put substitution rules in the
kernfeature if you like, and people might look at you funny but it’ll probably work fine. The only time this gets critical is when we are talking about (a) features which are selected by the user interface of the application doing the layout (for example, thesmcpfeature is usually turned on when the user asks for small caps, and it would be bizarre - and arguably wrong - if this also turned on additional ligatures), and (b) more complex fonts with a large number of rules which need to be processed in a specific order. Getting things in the right place in the processing chain will increase the chances of your font behaving in the way you expect it to, and, more importantly, will reduce the chances of features interacting with each other in unexpected ways.
Let’s suppose we are implementing a font for the Takri script of north-west India. There’s no Script Development Standard for Takri, so we’re on our own. We’ve designed our glyphs, but we’ve found a problem. When a consonant has an i-matra and an anusvara, we’d like to move the anusvara closer to the matra. So instead of:
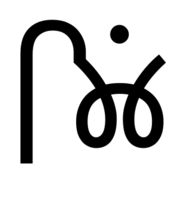
we want to see:
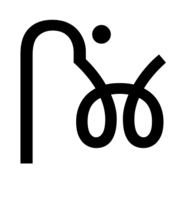
We’ve designed a new glyph iMatra_anusvara which contains both the matra and the correctly-positioned anusvara, and we’ve written a chained contextual substitution rule:
lookup iMatraAnusVara {
sub iMatra by iMatra_anusvara;
sub anusvara by emptyGlyph;
}
sub iMatra' lookup iMatraAnusVara @consonant' anusvara' lookup iMatraAnusVara;
This replaces the matra with our matra-plus-anusvara form, and replaces the old anusvara with an empty glyph. Nice. But what feature does it belong in?
First, we decide what broad category this rule should belong to. Are we rewriting the mapping between characters and glyphs? Not really. So this doesn’t go in the initial “pre-shaping” feature collection. It’s something that should go towards the end of the processing chain. But it’s also a substitution rule rather than a positioning rule, so it should go in the substitution part of the processing chain. It’s somewhere in the middle.
Second, we ask ourselves if this is something that we want the user to control or something we want to require. We’d rather it was something that was on by default. So we look through the collection of features that shapers execute by default, and go through their descriptions in the feature tags part of the OpenType spec.
For example, we could make it a required ligature, but we’re not exactly “replacing a sequence of glyphs with a single glyph which is preferred for typographic purposes.” dist might be an option, but that’s usually executed at the positioning stage. What about abvs, which “substitutes a ligature for a base glyph and mark that’s above it”? This feature should be on by default, and is required for Indic scripts; it’s normally executed near the start of the substitution phase, after those features which rewrite the input stream. This sounds like it will do the job, so we’ll put it there.
Once again, this is not an exact science, and unless you are building up extremely complex fonts, it isn’t going to cause you too many problems. So try to reason about what your features are doing, but feel free to copy others, and don’t worry too much about it.
Now let’s look at how to implement some specific features, starting with a few simple ones to get us started, and then getting to the more tricky stuff later.
Language-specific substitutes
We’ve already mentioned the Serbian form of the letter be (б), which should appear different to the Russian Cyrillic version. This is one example of a family of language-specific substitutes, which we can handle more or less in the same way.
First, we design our two glyphs, the Russian be (let’s call the glyph be-cy) and the Serbian variant, which we’ll call be-cy.SRB. We want a feature which is on by default, occurs early in the process, is pre-shaping (in that it rewrites the input glyph stream) and which substitutes localized forms - this is precisely what the locl feature was designed for. We look up the script tag for Cyrillic (cyrl) and the language tag for Serbian (SRB), and we create a rule that applies only when the input is tagged as being in the Serbian language. We want to do a one-to-one substitution - any Cyrillic be gets swapped out for a Serbian one - so we create a single substitution rule.
feature locl {
script cyrl;
language SRB;
sub be-cy by be-cy.SRB;
} locl;
Job done.
We can apply the same kind of substitution not just to base characters but also to marks and combining characters, although we need a little thought. In Polish, there’s an accent called a kreska which looks like an acute accent from other Latin scripts - and in fact, is expressed in Unicode as an acute accent - but is somewhat more upright and positioned to the right of the glyph. How do we create a font which distinguishes between the Western European acute accent and the Polish kreska, even though the Unicode characters are the same?
First, we should note that the Polish accent appears on some letters we may not have planned for: c, n, s and z - then again, we should also be aware that these letters also get an acute accent in other writing systems: Yoruba, Khmer, and Sanskrit transliteration amongst others. So we can’t just rely on having the Polish forms for these. We need - as with the vowels - to create two separate versions: one with the Western European acute, and one with kreska. We look at Adam Twardoch’s web site to help get the design of our Polish accents right, and we should now end up with two sets of glyphs: aacute, cacute, … and aacute.PLK, cacute.PLK and so on.
Now we know what we’re doing: we use the locl feature as before to substitute in these glyphs when the input text is in Polish:
feature locl {
script latn;
language PLK;
sub [aacute cacute ...] by [aacute.PLK cacute.PLK ...];
} locl;
This general pattern - language-specific substitution rules in the
loclfeature - can be used for a large number of localisation customizations, particularly those based on the Latin script (simply because they tend to be one-to-one glyph replacements.) Further examples of the pattern include Navajo forms of the ogonek accent, and choosing between variants of the letter U+014A LATIN CAPITAL LETTER ENG (Ŋ) - “N-form” variants in the case of Sami languages and “n-form” variants for African ones.
A detour about diacritics
We’ve looked at the mark-to-base positioning and composition/decomposition substitutions in previous chapters. Why, then, do we need to design separate glyphs for cacute and cacute.PLK - can’t we just design separate accents and have the OpenType system tie them together for us? In fact, why do we even need to include a cacute in our font at all? Can’t we just have the font automatically compose the glyph out of the c base glyph and the acute mark, and automatically position it for us? Hey, why can’t we do that for all our diacritic characters? As with many things in life, the answer is: sure, you can, but that doesn’t mean you should.
There are a few reasons why it’s best to design and include precomposed forms of all the accented glyphs you’re going to support, rather than rely on automatic composition. For one thing, there’s kerning: it’s much easier to test and edit the kerning for “Tå” in your font editor than adding tricky kern triplets in OpenType feature code.
Another problem is that some software (notably Adobe InDesign) doesn’t support it, and other software doesn’t support it in reliable ways. This is an important area to understand because it highlights the interplay between OpenType’s understanding of characters and glyphs and Unicode’s understanding of characters and glyphs.
Remember how we talked about Unicode normalization and decomposition in chapter 3, and how you can decompose a character like é (U+00E9 LATIN SMALL LETTER E WITH ACUTE) into two characters, U+0065 LATIN SMALL LETTER E and U+0301 COMBINING ACUTE ACCENT? That sounds very similar to the idea of having an “eacute” glyph which is made up of an “e” glyph and an “acutecomb” glyph. Similar… but unfortunately different.
As it happens, if your font provides a “e” and a “acutecomb” glyph but not a precomposed “eacute”, then some text layout systems will only render an e-acute if the input text is decomposed to U+0065 U+0301 (which is exceptionally rare) and will use a fallback font to display the precomposed form U+00E9. Others will automatically decompose a U+00E9 in the input stream to U+0065 U+0301 and display the two glyphs correctly. Some systems will correctly substitute a precomposed glyph for its decomposition specified using the ccmp feature, but then will fail to position the marks properly in the mark feature.
But having a precomposed glyph in the font will always work, both for composed Unicode characters like U+00E9 and for its decompositions, so that’s why having the font contain all the glyphs you are likely to support is a better way to go.
The letter “i”
The Latin letter “i” (and sometimes “j”) turns out to need special handling. For one thing, in Turkish, as we’ve mentioned before, lower case “i” uppercases to “İ”.
Unicode knows this, so when people ask their word processors to turn their text into upper case, the word processor replaces the Latin letter “i” with the Turkish capital version, LATIN CAPITAL LETTER I WITH DOT ABOVE U+0130. Fine. Your font then gets the right character to render. However, what about the case (ha, ha) when you ask the word processor for small capitals? Small capitals are a typographic refinement, which changes the presentation of the characters, but not the characters themselves. Your font will still be asked to process a lower case Latin letter i, but to present it as a small caps version - which means you do not get the advantage of the application doing the Unicode case mapping for you. You have to do it yourself.
In fact, any time the font is asked to make presentational changes to glyphs, you need to implement any character-based special casing by hand. What we say here for small-caps Turkish i is also valid for German sharp-s and so on.
Additionally, you may want to inhibit Turkish “i” from forming ligatures such as “fi” and “ffi”, while allowing ligatures in other Latin-based languages.
We’re going to look at two ways to achieve these things. I’m giving you two ways because I don’t want you just to apply it as a recipe for this particular situation, but hopefully inspire you to think about how to use similar techniques to solve your own problems.
Here’s the first way to do it, in which we’ll deal with the problems one at a time. We make a special rule in the smcp feature for dealing with Turkish:
feature smcp {
sub i by i.sc; # Amongst everything else.
script latn;
language TRK;
sub i by i.sc.TRK;
}
Oops, this doesn’t work. Can you see why not? Remember that the language-specific part of a feature includes all the default rules. The shaper sees a “i” and the smcp feature, and runs through all the rules one at a time. The default rules are processed first, so that “i” gets substituted for “i.sc”. Finally the shaper comes to the Turkish-specific rule, but by this point any “i” glyphs have already been turned into something else, so it does not match.
How about this?
feature smcp {
sub i by i.sc; # Amongst everything else.
script latn;
language TRK;
sub i.sc by i.sc.TRK;
}
Now the shaper gets two bites at the cherry: it first turns “i” into “i.sc”, and then additionally in Turkish contexts the “i.sc” is turned into “i.sc.TRK”. This works, but it’s ugly.
The ligature situation is taken care of using exclude_dflt:
feature liga {
sub f i by f_i;
script latn;
language TRK exclude_dft;
}
Now there are no ligature rules for Turkish, because we have explicitly asked not to include the default rules.
Here’s another, and perhaps neater, way to achieve the same effect. In this method, we’ll create a separate “Turkish i” glyph, “i.TRK”, which is visually identical to the standard Latin “i”. Now in the case of Turkish, we will substitute any Latin “i”s with our “i.TRK” in a locl feature:
feature locl {
script latn;
language TRK exclude_dflt;
sub i by i.TRK;
} locl;
What does that achieve? Well, the problem with ligatures is taken care of straight away, without any additional code. We create our liga feature as normal:
feature liga {
sub f i by f_i;
}
But we don’t need to do anything specific for Turkish, because in the Turkish case, the shaper will see “f i.TRK” and the rule will not match. The small caps case is easier too:
feature smcp {
sub i by i.sc; # Amongst everything else.
sub i.TRK by i.sc.TRK;
}
This has “cost” us an extra glyph in the font which is a duplicate of another glyph, but has made the feature coding much simpler. Both ways work - choose whichever best fits your mental model of how the process should operate.
Arabic, Urdu and Sindhi
In the various languages which make use of the Arabic script, there are sometimes locally expected variations of the glyph set - for instance, we mentioned the variant numbers four, five and seven in Urdu. The expected form of the letter heh differs in Urdu, Sindhi, Pakari and Kurdish. In Persian, a language-specific form of kaf (ک, U+06A9 ARABIC LETTER KEHEH) is preferred over the usual form of kaf (ك, U+0643 ARABIC LETTER KAF). All of these substitutions can be made using the language-specific locl feature trick we saw above.
“How do I know all this stuff?” Well, part of good type design is doing your research: looking into exemplars and documents showing local expectations, testing your designs with native readers, and so on. But there’s also a growing number of people collating and documenting this kind of language-specific information. As we’ve mentioned, the Unicode Standard, and the original script encoding proposals for Unicode, give some background information on how the script works. I’ve also added a list of resources to the end of this chapter which collects some of the best sources for type design information.
One of those resources is Jonathan Kew’s notes on variant Arabic characters in different scripts. He mentions there that some Persian documents may encode kaf with using U+0643, so fonts supporting Persian may wish to substitute kaf with the “keheh” form; other documents, however, might use U+06A9 to represent Persian kaf but retain the use of U+0643 to deliberately refer to the standard Arabic kaf - in which case you may not want to make that glyph substitution. Think about your intended audience when substituting encoded characters.
Arabic fonts additionally vary depending on their adherence to calligraphic tradition. When connecting letters together into word forms, calligraphers will use a wide variety of ligatures, substitutions, and adjustments to positioning to create a natural and pleasing effect, and Arabic fonts will reflect this “fluidity” to a greater of lesser degree. As you consider the appropriate ways of writing different pairs of letters together, the more ligature forms you envision for your font, the more complex you can expect the feature processing to be.
One important trick in Arabic feature programming is to make heavy use of chaining contextual substitutions instead of ligatures. Let’s consider the word كِلَا (kilā, “both”). A simple rendering of this word, without any calligraphic substitutions, might look like this: (Glyphs from Khaled Hosny’s Amiri.)

Running hb-shape --features='-calt' Amiri-Regular.ttf كِلَا confirms that no contextual shaping beyond the conversion into initial, medial and final forms is going on:
[uni0627.fina=4+229|uni064E=2@-208,0+0|uni0644.medi=2+197|uni0650=0@8,0+0|uni0643.init=0+659]
Obviously this is unacceptable. There are two ways we can improve this rendering. The first is the obvious substitution of the final lam-alif with the lam-alif ligature, like so:

But the second, looking at the start of the word, is to form a kaf-lam ligature:
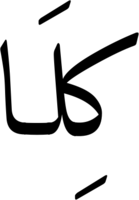
Ah, but… what if we want to do both? If we use ligature substitutions like so:
feature calt {
lookupflag IgnoreMarks;
sub kaf-ar.init lam-ar.medi by kaf-lam.init; # Rule 1
sub lam-ar.medi alef-ar.fina by lam-alef.fina; # Rule 2
} calt;
what is going to happen? The shaper will work through the string, seeing the glyphs ` kaf-ar.init lam-ar.medi alef-ar.fina. It sees the first pair of glyphs, and applies Rule 1 above, meaning that the new string is kaf-lam.init alef-ar.fina`. It tries to match any rule against this new string, but nothing matches.
Let’s now rewrite this feature using chained contextual substitutions and glyph classes. Instead of creating a lam-alef ligature and a kaf-lam ligature, we split each ligature into two “marked” glyphs. Let’s first do this for the lam-alef ligature. We design two glyphs, alef-ar.fina.aleflam and lam-ar.medi.aleflam, which look like this:
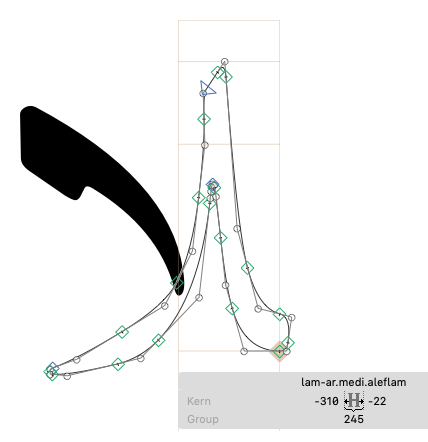
and then we substitute each glyph by its related “half-ligature”:
lookup LamAlef {
sub lam-ar.medi by lam-ar.medi.aleflam;
sub alef-ar.fina by alef-ar.fina.aleflam;
} LamAlef;
feature calt {
lookupflag IgnoreMarks;
sub lam-ar.medi' lookup LamAlef alef-ar.fina' lookup LamAlef;
}
Finally, we create our variant kaf, which we call kaf-ar.init.lamkaf, and now we can apply the kaf-lam substitution:
feature calt {
lookupflag IgnoreMarks;
sub kaf-ar.init' lam.medi by kaf-ar.init.lamkaf; # Rule 1
sub lam-ar.medi' lookup LamAlef alef-ar.fina' lookup LamAlef; # Rule 2
}
Now when the shaper sees kaf lam alef, what happens? Kaf and lam match rule 1, which substitutes the kaf for its special initial form. Next, lam alef matches rule 2, which chains into the “LamAlef” lookup; this converts the first glyph to lam-ar.medi.aleflam and the second to alef-ar.fina.aleflam.
It’s a little more convoluted, but this way we have a substitution arrangement that works not just by ligating a pair at a time, but which allows us to continue transforming glyphs across the string: alef-lam works, as does lam-kaf, but they also both work together.
Other complex scripts
Designing for Indic scripts such as Devanagari is pretty much the same as any other script: know your script, do your research, read the Microsoft script development guidelines. In terms of OpenType Layout, these guidelines contain a helpful list of features you will need to implement, and some hints for how you should implement them.
But this is made complicated by the fact that the shaping engine contributes its own knowledge to the process. Just as how, in Arabic, the shaping engine will automatically “call” the init, medi and fina features to obtain the correct glyphs for characters in certain positions, Shaping engines like Harfbuzz and Uniscribe contain code which handle various special cases required by different script systems - syllable reordering in Indic scripts, jamo composition in Hangul, presentation forms in Hebrew, adjustment of tone mark placement in Thai, and so on.
As we’ve already mentioned, OpenType Layout is a collaborative process, and this is especially true for complex scripts. There is a complex dance between what the shaper signals to your font and what your font signals to the shaper. To create a font which performs correctly, you need to have knowledge both of what the shaper is going to do on your behalf, and also how you are going to respond to what the shaper does.
Let’s take Devanagari as an example.
First, the shaper will move pre-base matras (such as the “i” vowel) before the base consonant, and any marks after the base. But what is the base consonant, and what is a mark? Here’s the thing: your font helps the shaper decide.
Consider the made-up syllable “kgi” - ka, virama, ga, i-matra. Without special treatment, we can expect the vowel to apply to the base consonant “ga”, like so:

But if the ka takes a half-form, (which of course it should in this case) then the matra applies to the whole cluster and should appear at the beginning. By adding the half-form feature to your font
feature half {
sub ka-deva halant-deva by k-deva;
} half;
you signal to the layout engine that the matra should cover the whole cluster:

Again, this is something we can see clearly with the hb-shape utility:
$ hb-shape --features='-half' Hind-Regular.otf 'क्गि'
[dvKA=0+771|dvVirama=0@-253,0+0|dvmI.a05=2+265|dvGA=2+574]
$ hb-shape --features='+half' Hind-Regular.otf 'क्गि'
[dvmI=0+265|dvK=0+519|dvGA=0+574]
So the features defined in your font will change the way that the shaper applies glyph reordering - the script development specs calls this “dynamic character properties” - and conversely, if you do not provide appropriate substitutions for half-forms then your glyphs may not appear in the order you expect!
Similar dynamic properties apply in other features too. The shaper will test each consonant-halant pair to see if the half or rphf (reph form, above-base form of the letter ra) features apply to them and create a ligature. If they do, the consonant is not considered a base.
if the reph form is part of a mark class, it will be moved to after the base.
To see these reorderings in action, I created a dummy font which simply encodes each glyph by its Unicode codepoint. I then added the following features:
languagesystem DFLT dflt;
languagesystem dev2 dflt;
feature half {
# ka virama -> k
sub uni0915 uni094D by glyph01;
} half;
feature rphf {
# ra virama -> reph
sub uni0930 uni094D by glyph02;
} rphf;
Let’s use this to shape the syllable “rkki” (ra, virama, ka, virama, ka, i-matra):
$ hb-shape Devanagari-Test.otf 'र्क्कि'
[glyph02=0+600|uni093F=2+600|glyph01=2+600|uni0915=2+600]
The ra-virama turned into our reph form; the ka-virama turned into a half form; and the sequence was reordered to be “reph i-matra k ka”. Oops, that’s not quite right. We want the reph form to appear at the end of the sequence. We’ll add another line to our feature file, stating that glyph02 (our “reph” form) should be interpreted as a mark:
markClass glyph02 <anchor 0 0> @reph_is_mark;
How does that change things?
$ hb-shape Devanagari-Test.otf 'र्क्कि'
[uni093F=0+600|glyph01=0+600|uni0915=0+600|glyph02=0+600]
That’s fixed it - the “mark” reph form is moved to the end of the syllable cluster, where we want it.
If you want to get clever and have a variant reph form to match the i-matra, have a look at the feature file for Indian Type Foundry’s Hind family.
The rphf and half features are tested against consonant-virama pairs; when a virama appears before a consonant, the pair is tested to see if any pre-base forms (pref feature), below-base forms (blwf) or post-base forms (pstf) are substituted; if so, these forms will not be considered the base consonant. Pre-base consonants identified by substitutions in the pref feature will also be reordered.
The script development specs advise that all consonants should have a nukta form, implemented in the nukt feature. While you could do this by providing positioning information for the nukta on the base, the Indian Type Foundry recommends providing substitution glyphs with nuktas in order to avoid problems when forming ligatures. You will also want to provide rakaar forms using the rkrf feature; these will be processed after the nukta and akhand ligatures are processed, so will take the output of these features:
feature nukt {
sub ka-deva nukta-deva by kxa-deva;
}
feature rkrf {
sub ka-deva halant-deva ra-deva by kra-deva;
# Also include glyphs output from nukta feature
sub kxa-deva halant-deva ra-deva by kxra-deva;
}
The Universal Shaping Engine
In the previous section we looked at how shapers contain specialist knowledge, automatically activating particular features and performing glyph reordering based on the expectations of a particular script. The Indic shaper has a lot of linguistic information in it - it knows how to reorder glyphs around the base consonant, and it further knows that when half forms or reph forms are present, the way that reordering happens should change.
Of course, there’s a problem with this. If the shaper contains all the knowledge about how to organise a script, that means that when a new script is encoded and fonts are created for it, we need to wait until the shaping engines are updated with new handling code to deal with the new script. Even when the code is added to the shaper, fonts won’t be properly supported in older versions of the software, and in the case of commercial shaping engines, it may not actually make economic sense for the developer to spend time writing specific shaping code for minority scripts anyway.
After overseeing the development of far more script-specific shapers than one person really should, Andrew Glass of Microsoft wondered whether it would be possible to develop one shaping engine for all of Unicode. A similar endeavour by SIL called Graphite attempts to acts as a universal shaping engine by moving the script-specific logic from the shaper into the font: Graphite “smart fonts” contain a bytecode program which is executed by the shaper in place of the shaper’s script-specific knowledge. In Glass’ idea of the Universal Shaping Engine, however, the intelligence is neither in the font nor in the shaping engine, but provided by the Unicode Character Database.
Each character that enters the Universal Shaping Engine is looked up in the Unicode Character Database. Based on its Indic Syllabic Category, General Category, and Indic Positional Category entries, is placed into one of twenty-four character classes, further divided into 26 sub-classes. The input characters are then formed into clusters based on these character classes, and features are applied to each cluster in turn.
One problem that the USE attempts to solve is that the order that characters are encoded in Unicode is not the same as the order in which their respective glyphs are meant to be displayed. A USE shaper looks at the character classes of the incoming input and forms them into a cluster by matching the following characteristics:
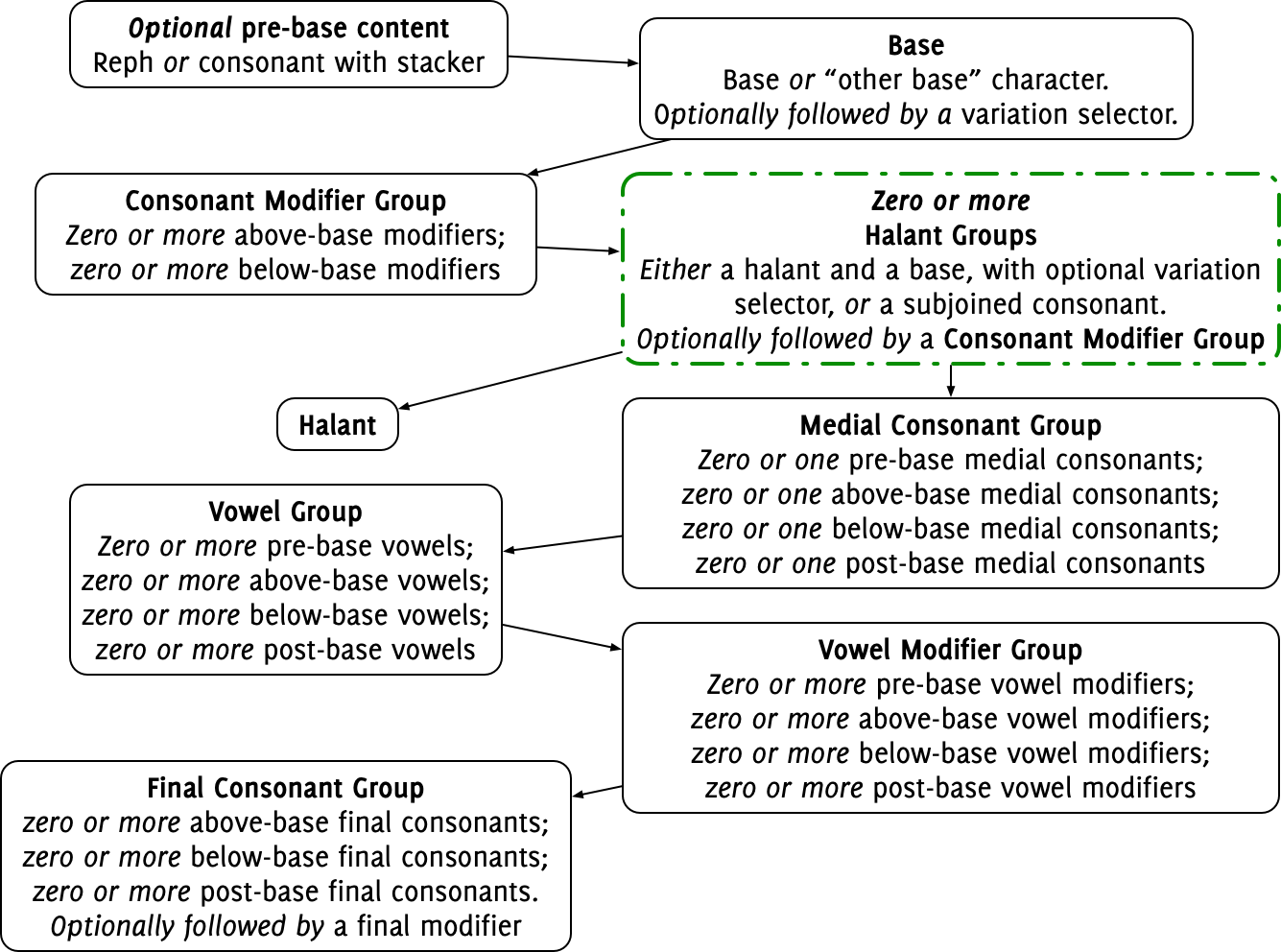
If you want a more formal grammar for a USE cluster, you can find one in the Microsoft script development specs.
But the USE expects those characters to be formed into a glyph which looks like this:
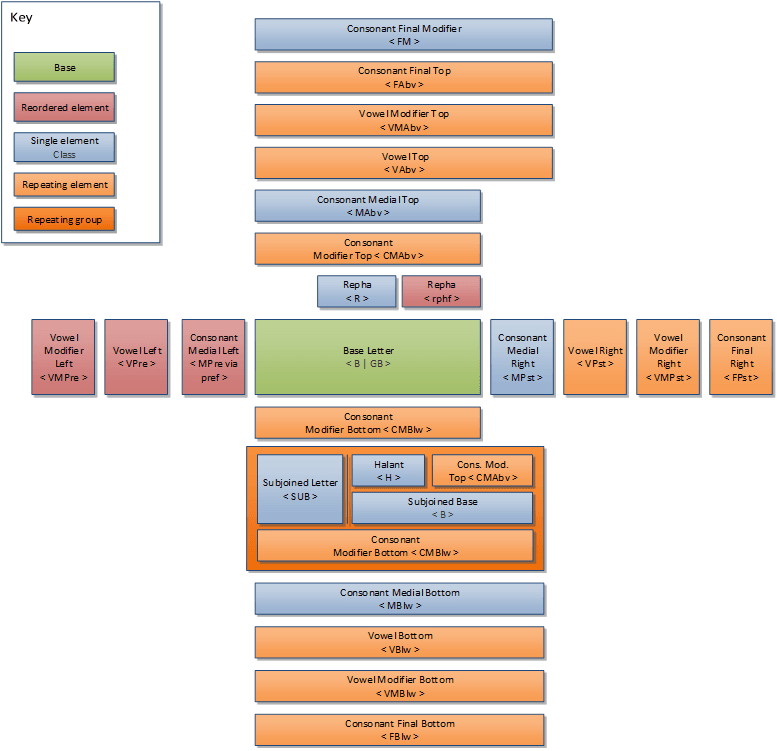
For instance, in Telugu, we know that the series of characters ఫ్ ట్ వే should be formed into a single cluster (ఫ్ట్వే), because it is made up of a base character ఫ, followed by two halant groups (virama, base consonant), and a final top-positioned vowel. The script development spec mentioned above explained how these categories are derived from the Indic Positional Category and Indic Syllabic Category information in the Unicode Character Database.
This “computational” model of a cluster does not know anything about the linguistic rules used in real-life scripts; you can create valid USE clusters which would be shaped “correctly” according to the script grammar defined in the specification, even though they have no relationship with anything in the actual language. For example, we can imagine a Balinese sequence made up of the following characters:
- ᬳ BALINESE LETTER HA, Base
- ᬴ BALINESE SIGN REREKAN, Consonant modifier above
- Halant group:
- ᭄ BALINESE ADEG ADEG, Halant
- ᬗ BALINESE LETTER NGA, Base
- ᬴ BALINESE SIGN REREKAN, Consonant modifier above
- Halant group:
- ᭄ BALINESE ADEG ADEG, Halant
- ᬢ BALINESE LETTER TA, Base
- Vowels:
- ᬶ BALINESE VOWEL SIGN ULU, Vowel above
- ᬹ BALINESE VOWEL SIGN SUKU ILUT, Vowel below
- ᬸ BALINESE VOWEL SIGN SUKU, Vowel below
- ᬵ BALINESE VOWEL SIGN TEDUNG, Vowel post
- Vowel modifiers:
- ᬀ BALINESE SIGN ULU RICEM, Vowel modifier above
- ᬁ BALINESE SIGN ULU CANDRA, Vowel modifier above
- ᬄ BALINESE SIGN BISAH, Vowel modifier post
- Final consonants:
- ᬃ BALINESE SIGN SURANG, Consonant final above
It’s complete gobbledegook, obviously, but nevertheless it forms a single valid graphemic cluster according to the Universal Shaping Engine, and Harfbuzz (which implements the USE) bravely attempts to shape it:

When USE has identified a cluster according to the rules above, the first set of features are applied - locl, ccmp, nukt and akhn in that order; next, the second set of features - rphf and pref in that order; then the third set of features - rkrf, abvf, blwf, half, pstf, vatu and cjct (not necessarily in that order).
After these three feature groups are applied, the glyphs are reordered so that instead of their logical order (the order that Unicode requires them to be entered in a text) they now represent their visual order (reading from left to right). Rephs are keyed into a text before the base character, but are logically after it in the glyph stream. So in the Śāradā script used in Kashmir, we can enter 𑇂 (U+111C2 SHARADA SIGN JIHVAMULIYA) 𑆯 (U+111AF SHARADA LETTER SHA), and this is reordered by the shaping engine like so:
$ hb-shape NotoSansSharada-Regular.ttf '𑇂𑆯'
[Sha=0+700|Jihvamuliya.ns=0@-680,0+0]
Notice how the Jihvamuliya (reph) has been placed after the base glyph in the glyph stream (even though it’s then positioned on top).
Similarly, glyphs representing pre-base characters (specifically pre-base vowels and pre-base vowel modifiers - and glyphs which have been identified with the pref feature, which we’ll talk about in a minute) are moved to the beginning of the cluster but after the nearest virama to the left. Here we have a base (U+111A8 BHA), a halant (U+111C0 VIRAMA), another base (U+11193 GA), and a pre-base vowel (U+111B4 VOWEL SIGN I).
$ hb-shape NotoSansSharada-Regular.ttf '𑆨𑇀𑆓𑆴'
[Bha=0+631|virama=0+250|I=2+224|Ga=2+585]

The i-matra has been correctly moved to before the base GA, even though it appeared after it in the input stream.
Pre-base consonants, however, are not reordered. If you want to put these consonants before the base in the glyph stream, you can do so by mentioning the relevant glyph in a substitution rule in the pref feature. For example, to move a Javanese medial ra (U+A9BF) to before the base, you create a rule like so:
feature pref {
script java;
sub j_Jya j_RaMed' by j_RaMed.pre;
} pref;
The j_RaMed.pre glyph will be moved before the j_Jya by the shaper. When I say the glyph should be “mentioned” in a substitution rule, I do mean “mentioned”; you can, if needed, substitute a glyph with itself, just to tell the shaper that you would like it moved before the base. This code reorders a Tai Tham medial ra, by ensuring that the pref feature has “touched” it:
feature pref {
script lana;
sub uni1A55 by uni1A55;
} pref;
In days before the Universal Shaping Engine, fonts had to cheat, by swapping the characters around using positioning rules instead. Here in Noto Sans Tai Tham, the base (TAI THAM LETTER WA) is shifted forward 540 units, while the prebase medial ra is shifted backwards 1140 units, effectively repositioning it while keeping the characters in the same order in the glyph stream:
$ hb-shape NotoSansTaiTham-Regular.ttf 'ᩅᩕ'
[uni1A45=0@540,0+1103|uni1A55=0@-1140,0+100]
Next, after re-ordering, positional features (isol, init, medi, fina) are applied to each cluster, and finally the usual run of substitution and positioning features are applied as normal. (See the USE script development spec for the full list.)
The Universal Shaping Engine is a tremendous boost for those creating fonts for minority scripts; it allows font development to press ahead without having to wait for shaping engines to encode script-specific logic. However, the shaping engine still needs to hand off control of a specific script to the USE for processing, rather than handling it as a normal (non-complex) script. This means there is still a list of scripts within the shaping engine, and only scripts on the list get handed to the USE - or perhaps another way to put it is that the shaping engines still have script-specific routines for some scripts, but not for others. In fact, the list of languages which use the USE (as it were) are different between different engines - see John Hudson’s USE presentation for more details.
Rather than having to write a new shaper for each script, shaping engine maintainers now only have to add a line of code to the list of USE-supported scripts - but they still have to add that line of code. Supporting new scripts is easier, but not automatic. (I hope that one day, USE will become the default for new scripts, rather than the exception, but we are not there yet.)
Additionally, the USE’s maximal cluster model (which allows us to produce crazy clusters such as the Balinese example above) more or less fits all scripts, although John Hudson has found an exception in the case of Tai Tham. In his words, “the Universal Shaping Engine turns out to be not quite universal in this sense either. But it’s pretty darn close, and is a remarkable achievement.” It most certainly is.
Resources
To finish, here is a list of resources which may help you when designing and implementing for global scripts:
- Latin diacritics design:
- The Insects Project - a downloadable book on issues of Central European diacritic design
- Problems of Diacritic Design for Latin script text faces
- Polish diacritics how-to (Adam Twardoch)
- Filip Blažek’s Diacritics project
- Context of Diacritics analyses diacritics by frequency, combination and language
- Danny Trương’s Vietnamese Typography
- Guidance on specific characters:
- thorn and eth (Gunnlaugur Briem)
- Tcomma and Tcedilla
- German capital sharp s, and OpenType feature code to support it
- Microsoft’s script development specifications: Latin, Cyrillic, Greek; Arabic; Buginese; Hangul; Hebrew; Bengali; Devanagari; Gujarati; Gurmukhi; Kannada; Malayalam; Oriya; Tamil; Telugu; Javanese; Khmer; Lao; Myanmar; Sinhala; Syriac; Thaana; Thai; Tibetan
- Arabic resources:
- Indic script resources:
- The Indian Type Foundry has an annotated feature file for Devanagari.
- Script databases:
- Omniglot is an online encyclopedia of scripts and languages.
- ScriptSource is similar, but includes an annotated version of the Unicode Character Database for each codepoint. See, for example, the page about LATIN SMALL LETTER EZH.
- Eesti Keele Institute letter database tells you what glyphs you need to support particular languages.