Regression works!
Yesterday I mentioned the idea of using regression instead of one-hot encoding for co-ordinates. Which is, let’s face it, a much more sensible approach. I guess what held me back was a couple of things: my experience of doing regression with neural networks has not been great so far, and that there is an additional structure in off-curve points in that, for a smooth connection, the incoming angle between a handle and a node is always equal to the outgoing angle between the node and the next handle. But anyway, I tried it, and after many epochs and reducing the LR substantially, I started getting things like this:
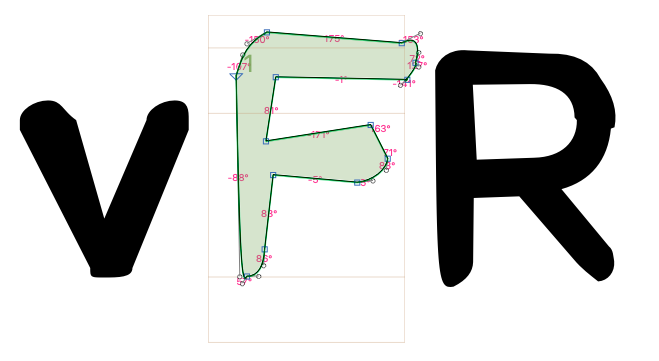
Not bad, eh? Of course, this is rather similar to the font I showed the network as input… I’m going to try again with a range of fonts in the same style and see if it can come up with something in between. I suspect that differing X-heights and cap-heights will mess that up. Currently I’m just gathering all the X coordinates into one vector and all the Y coordinates into another and normalizing each vector with a StandardScaler. But I suppose I could divide them by the font’s em-width and cap-height respectively; the problem then is knowing how to de-normalize them again when generating a new glyph.
Fun fact: I am getting much better output with a small number of LSTM nodes (order of 128) rather than a huge network, and better with one LSTM layer than more than one. Not sure why this is, but the huge networks seem to really latch on to the (1,2,2,1) pattern of instructions - on-curve, off-curve, off-curve, on-curve) and just go around and around making nodes, but never actually get around to emitting any end-of-contour or end-of-glyph instructions.