fontmetrics library
So, I couldn’t help it; I’ve fallen off the neural kerning wagon again, thanks to a fascinating article by Sebastian Kosch describing an “attention-based approach” to the spacing/kerning problem.
I have to admit that I am having problems fully understanding Sebastian’s approach, because it contains a number of new concepts that I understand independently, but I am not sure how they relate to one another. So I am working my way through his code, refactoring it and documenting it so that I know what is going on.
But going through the code as a means of understanding the algorithm has highlighted again something that I found when I was working on atokern. The real difficult part of building a neural kerning system is not, paradoxically, building the model; no, the real problem is actually extracting the data out of the fonts in a correct and coherent manner in the first place. I wasted a huge amount of time because I had accidentally cropped out descenders, or included descenders, or used the same scale for fonts with different x-heights, or divided by em-width, or not divided by em-width, and so on.
Even going through Sebastian’s code, I find myself staring at lines like:
right_ldepth = np.argmax(
self.glyph_pixels_cropped[right] > cutoff,
axis=1) + 10000 *
(np.max(self.glyph_pixels_cropped[right], axis=1) <= cutoff)
and thinking “Sure, that’s fascinating, but what does it actually do?” I really believe that code should be declarative in the sense that it should tell the reader what it is trying to achieve, rather than how it is trying to achieve it.
So to try to solve both the correctness/coherence problem of dealing with font data and the declarative, semantic issue, I have been working on a library which specializes in providing numerical and statistical data about fonts. Sebastian’s code above would be replaced by:
right_ldepth = font.glyph(right).as_matrix().left_contour()
Here’s another example of using the library which I have unimaginatively named fontmetrics:
font = Font("/Library/Fonts/AGaramondPro-Regular.otf")
Q = font.glyph("Q")
fx, axarr = plt.subplots(2,2)
axarr[0,0].imshow( Q.as_matrix() )
axarr[0,1].imshow( Q.as_matrix().with_sidebearings().mask_to_x_height() )
QQ = Q.as_matrix().with_sidebearings()
ycoords = np.arange(0,QQ.shape[0]) * -1
axarr[1,0].plot( QQ.left_contour(max_depth=font.m_width), ycoords )
axarr[1,1].plot( QQ.right_contour(max_depth=font.m_width) * -1, ycoords )
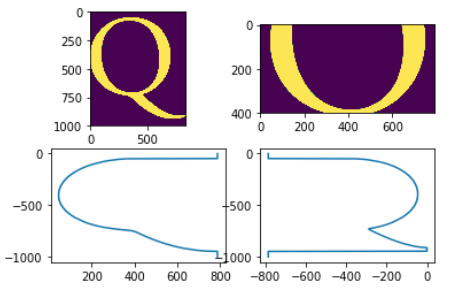
Once it’s a bit more developed and documented (and I’ve rewritten Sebastian’s code in terms of it), I’ll upload it to GH. But that’s what I’ve been playing with this week.