The State of AI Font Generation
Two disclaimers: First, this article was entirely human generated; no AI was involved in the writing. Second, I have spent a lot of time this year attempting to train a glyph generation model. I want to be up front about this because I know that for certain people, this will discredit me entirely, and I don’t want you to find out afterwards and feel betrayed. But then, would you rather read an article about AI font generation written by someone who didn’t have any experience of it?
There’s been a lot of discussion recently about the ability of machine learning models to generate new fonts, or “fill in” existing fonts (by expanding the glyphset or design space), much of it prompted by this thread on Typedrawers. As part of that thread, Dave Crossland wrote:
Impallari appears to have been the first. Eric’s become second. I hope there’ll be a third.
I’m not going to talk here about the ethical or legal side of font generation, about whether you should or shouldn’t do this. These are important questions, but not for here; but my reaction when I read that was “Eric wasn’t the second; he wasn’t even the twenty-second - it just that all the others aren’t in your face right now.”
So the point of this article is to try to survey some of the development in font generation research, to present a clear-eyed view of what’s out there, how it works, and what I expect coming down the line. Because more will be coming down the line. People are going to work on this problem, whether we want them to or not. So whether your instinct is to welcome it or critique it (or of course both), let’s make sure we’re aware of it and we understand it.
But let’s also use it as an opportunity to understand ourselves as well. During my investigations, I noticed a couple of factors, a couple of gaps, and I think perhaps talking about these gaps is going to be the real takeaway from this post, rather than the technical stuff. I’m talking about the gaps between type designers and ML engineers, and also the gaps between Western type designers and Chinese/Japanese/Korean type designers.
The obligatory Two Cultures reference
One feature I’ve noticed is a very obvious lack of collaboration across disciplines, between ML researchers and type designers. I’ve certainly noticed a lack of collaboration between ML researchers and type engineers - as I look into the code for some of the models, I shudder to read how glyph outlines and rasterizations are being extracted from fonts; it’s clear that nobody from type-world has had any input into this at all. But more generally, I can see that there is also a lack at the quality control level; what ML engineers consider a typographic success would be something that a type designer would never dare share in public. I’m not just thinking of this thread, but also stuff like Neural Axis Variations - a genuinely interesting idea which probably could be well implemented, but clearly needed a type designer to review it before publication.
This is not “a fully functional variable font”.
I don’t say this to mock people’s work. The whole point is that you don’t know what you don’t know. I have a theory about why this is: when it comes to collaboration with type designers, I think there is an obvious question of perceived need.
ML researchers are really used to working with computer graphics. It’s something that they do all the time and do really well. And, as I argued in the big TypeDrawers thread, “type design is very deceptive because it’s easy to draw a series of recognisable letter forms” and that makes it hard for you to realise that you need feedback. If your ML model outputs a long string of amino acids, you know that you’re going to need a biologist to tell you whether it makes sense or not. Collaboration across disciplines is so obviously necessary in such a situation that you wouldn’t think not to.
But if you’re a researcher used to working with computer graphics and your task is to draw the letter ‘a’… well, everyone knows what an ‘a’ looks like. You don’t need professional input for that. (Spoiler alert: turns out you do!)
And at the same time… how can I put this delicately? Even if ML researchers did reach out to the typographic community in order to collaborate on AI-assisted font generation, they may not necessarily receive a warm and hearty welcome. It’s kind of a touchy subject. Type people have a habit of asking awkward questions about ethics and legality. And on top of that, nobody wants to be the one responsible for putting themselves and their peers out of work. You know, I get that.
So there is a paradox here: that AI generated font design can only come out of deep engagement with the typographic community if it’s going to be effective and high quality, and right now the typographic community doesn’t actually want effective and high quality AI generated font design.
Which I guess is good news for the typographic community, right? Researchers produce bad models because they either don’t seek out typographers or typographers won’t work with them, and type designers see the output of the bad models and feel reassured that their jobs are safe. A neat closed loop.
Except, that’s such a Western perspective.
The other two cultures
One of the main pushbacks from designers about AI tooling for font design is that it has to make sure that it’s not just “doing the fun bit”. Designers draw letterforms because they like drawing, and so AI tools which draw letterforms - even decent letterforms - but don’t help with the “boring bit” are counterproductive. The boring bits of type design are different for each designer: spacing, kerning, glyphset expansion and language support, designspace expansion. We can disagree about that. But one thing that does seem to be a clear consensus is that drawing the actual shapes is the fun bit, and there’s no desire for an AI model which takes that away.
Except, not all of us have the same objectives. When you have a hundred or even a thousand characters to draw, working out how your design inhabits each of those characters is a fun and interesting puzzle to solve.
When you have a hundred thousand characters to draw, it stops being quite so fun and interesting and turns into a royal pain in the arse. Chinese font design is a different kettle of fish altogether, requiring teams of designers many years of work to produce a single font. Of course, we have some automations such as variable components which can help bring that down, but even so… drawing is not the “fun bit” of Chinese type design.
While I was looking at the deepvecfont-v2 codebase, I noticed that all of the model training data was made available. You can download the whole data dump, all the fonts. This is kind of unusual. You don’t often see font-based ML projects making their training data available, largely because it allows you to see quite how many commercial fonts were, uh, “accidentally” caught up in the dragnet of fonts that the researchers scraped off the Internet. But this one was different. A huge cache of commercial Chinese fonts were made publicly available as part of the training data release for the deepvecfont-v2 project. How is this possible? Is this even legal?
Well, a little note at the bottom of the repository says:
Please note that all the Chinese fonts are collected from Founder, and the fonts CANNOT be used for any commercial uses without permission from Founder.
To spell that out more explicitly: While Western foundries are explicitly saying “you can’t use our fonts to train AI models”, Founder Type, one of the main Chinese type foundries, have partnered with a team researching AI-based font generation and said “We are giving anyone on the Internet a free license to our entire Chinese font catalogue but only if you use it to train an AI model.”
That… probably wouldn’t happen in the West. Different situations have different objectives. Chinese type foundries welcome AI font research because it can help them with their “boring bit”. They have a serious commercial interest in the problem of “few-shot font generation”: the idea that I draw fifty glyphs in a particular style, and the computer just fills in the rest. Western foundries do not, on the whole, share this enthusiasm. (This was a dynamic which was very much in evidence at ATypI Copenhagen last year.)
What this means is that a lot of the interesting work going on in terms of AI font generation is happening in China and Japan, and is happening with foundry support. And while the current state of Latin font generation is, well, pretty poor, AI font generation in Chinese is already production-ready.
They’re already using it.
This is bad, right? If they can generate production-ready Chinese fonts, then they’re coming for Latin type design soon. Well, maybe. But maybe not. Look around you and you will discover that there aren’t production-ready Latin font generation models right now, and those which do exist are pretty woeful. Why is this? What is going on? Some ideas later.
The revolution will not be a TypeDrawers thread
For now, let’s finally take a look at the current state of font generation. We’ve established that ML engineers are not working in collaboration with type designers, and what that means is that you aren’t going to find out about font generation advances in the typography media. You’re going to need to start looking where people in the ML community communicates with one another: conference papers and pre-prints, and more specifically Arxiv. Arxiv is where scientists share in-progress research papers, and in particular, the “Computer Vision and Pattern Recognition” (cs.CV) subsection is where all the ML-y graphic-y stuff ends up. If you want to find out what’s actually going on in font generation research, that’s where you will need to go. A search for “font” on arxiv today turns up 328 papers. Not all of them are about font generation, but a lot of them are. Most of those, as predicted, are from China, Japan and Korea. Many of those are, predictably, about the “few-shot font generation” problem: draw me a 50,000 character font from 50 references.
Filip Paldia put together quite an exhaustive list of state-of-the-art projects up to early 2024. But the field has developed considerably since then. Let’s take a quick tour of them, and bring things up to date. The following sections will be representative, not exhaustive. If you’re really into this, you’re best placed doing your own searches on Arxiv…
Generative Adversarial Networks
Early font generation work (2018-2023) tended to be built on Generative Adversarial Networks, the same technology underlying image generators like DALL-E (first edition). GANs are comprised of two models, the “forger” and the “detective”; the forger tries to create an image and the detective tries to detect whether or not it’s machine-generated. They keep iterating on this task until the forger manages to create an image which the detective thinks is real, at which point it’s good to go.
For font generation, conditional GANs were used - we don’t just try to produce any image, but we give the GAN a particular glyph (content) and a particular style, and try to “forge” a glyph image matching that style. Font GAN model naming was incredibly unimaginative. They went:
- DG-Font (2021): Not quite the OG, but one of the most influential.
- LF-Font (2021): Saw “style” as a hierarchical set of component level features.
- MX-Font (2021): Multiple component-level “experts” learn to produce different parts of a glyph. (There’s now an MX-Font++ but I haven’t looked at it yet.)
- CG-GAN (2022): A few points at least for trying a different naming scheme.
- FS-Font (2022): Tries to further identify the local details (terminals etc.) which define font style.
- CF-Font (2023): Fuses style and content into a single prior for training.
- DA-Font (2025): Tried various ways to improve corners and an “elastic mesh” to improve structure.
GANs went out of fashion because they’re a real pain to train, and in the font application, they’re often pretty blurry. The fact that DA-Font came out last year and is still GAN based is pretty interesting. As you can see from the timeline, the real struggle for GANs is working out how to express “style” in a way that makes sense at the local level.
Diffusion models
After GANS, the next technique in image generation was diffusion models - used in image generators like DALL-E 2, Midjourney and Stable Diffusion, and pretty much everything else these days. These work by taking a random noise image and progressively “denoising” it until you’re left with the correct pixels for your glyph. They’re easier to train, especially at higher level of resolution. And because ML researchers really are very bad at naming things, for fonts, we have:
- Diff-Font (2023, code): First application of diffusion to few-shot font generation.
- FontDiffuser (2024, code): Lots of people think this is a good baseline, but it’s still pretty darned blurry. Importantly, it’s tested both on Chinese and Latin.
- HFH-Font (2024): Notable because Zhouhui Lian, one of the authors, is behind a lot of these models.
- DiffuFont (2025, no preprint, code): Very Chinese specific, uses a curated reference set of content and style references.
These are pretty good, but they’re also super slow because they progressively generate a glyph image over a number of steps.
Autoregressive models
Autoregressors are some of the first things you learn how to make when you’re learning ML. These are models which learn to predict their own inputs, which sounds really stupid, except that they first transform those inputs into a “latent space”, a simplified representation which forms a surface over the set of all possible inputs. You can use this for cool stuff like compression (my image is just 64 numbers now) and interpolation on the font-space surface. (“Generate a font 70% of the way between Times and Roboto” might be interesting; “Generate a letter 70% of the way between e and k” perhaps less so.) Shove some conditioning in there and you’ve got style transfer. Continuing with the naming scheme, we have:
- VQ-Font (2024, code): We turn the glyphs into a sequence of codes in latent space, then work out how to generate a new sequence of codes for a new glyph.
- IF-Font (2024, code): This is super Chinese-specific, as it uses Ideographic Description Sequences to condition the image generation.
- GAR-Font (2026, code): This is the state of the art, at least for autoregressive models.
These all work on the same two-step principle: train a tokenizer to reduce glyph images into latent space, then train a generator to produce new images. They tend to work on small (64x64) rasters although it’s possible to expand to 128x128 if you have the patience and GPU memory. They take forever to train.
Diffusion Transformers
This is going to be the new hotness. I should pay more attention to these but life is short and this essay is already too long. The first out of the gate is UTDesign (2026, code). It’s a general model of text creation rather than simply font generation - who needs an actual font if you can directly add text onto your image? There will be more.
What’s going on with vectors?
All of the above projects work on raster images with some kind of post-processing vectorization step. And yes, I’m aware that vectorization of glyph images has been historically very bad, which is one part of the perceived lack of quality of AI-generated fonts. But that is changing; we are getting better vectorization tools, including my own Glyph Tracy and Eli Heuer’s img2bez.
This is partly because a lot of computer vision research and knowledge already exists around handling raster images. In other words, glyphs are just pictures and we know how to make computers draw pictures. And there are other reasons why vectors are harder to reason about for an ML model:
- Long sequences are hard to predict. Did I mention that most of the research comes out of China? Chinese glyphs are complex with many components, many points for each glyph, meaning that the sequences involved in processing vector representations of Chinese glyphs become very long. When training ML models on sequential information, the longer the sequence, the harder it is to train, as errors in early parts of the sequence accumulate and throw the model further and further off track as you go along.
- Vector sequences are non-local. By which I mean, the test of whether or not your character looks right is fundamentally visual. You end up comparing pixels at some point. If you’re generating pixels and the pixels don’t look right, you just change the pixels that don’t look right. That’s easy. But the relationship between a sequence of vector commands and final “look” of glyph is much more complex. A change to the length of one handle affects a large number of pixels.
- It’s hard to compare vector images. Machine learning is fundamentally a feedback loop between trying something and getting feedback on whether or not it worked. We have really good metrics for determining whether a generated raster image looks like it’s supposed to: structural similarly, pixel loss, perceptual modelling. But we don’t have good metrics for how to compare vector sequences, and we certainly don’t have metrics for how to tweak those vector sequences to align them better with what they’re supposed to be. (Yes, I know the differential rasterizer exists but hush, I’m simplifying.) No metrics, no feedback loop, no training.
So pretty much all existing research is going down the line of raster images plus vectorization. There are four projects worth talking about which deal with vectors:
- Deepvecfont and Deepvecfont-v2 (remember those guys who got a license for all the Foundry Type fonts?). The only reason it’s worth mentioning this is to note that the people involved are now working on raster-based approaches instead, so that tells you something.
- Vecfusion, an Adobe/academia collaboration. This is interesting because it solves both the few-shot problem and the interpolation problem (give me a font half way between Arimo and Dancing Script) in vector space, for Latin fonts. Why isn’t this everywhere yet, if it’s as good as they say it is? I’m not sure. Partly because these papers tend to be, if we’re honest, a bit of a rigged demo where you show off the most convincing results and hide the ones which are a bit crap. But also partially because commercial involvement means that it’s probably going forward inside of Adobe if it’s going anywhere. You will probably find bits of it in Adobe Firefly and quiver.ai.
- Neural Axis Variations, mentioned above. Tries to learn how to predict the deltas values required to move a font from one part of design space to another, allowing you to expand designspaces automatically from a single vector instance. Let’s charitably say it’s not there yet but it’ll clearly be the basis for more work later.
- Unnamed research project. I happen to know there’s people at Nagoya Institute of Technology working on vector font generation; I also happen to know they’re struggling to work out how to represent a smooth manifold of latent space for vector images.
I have Ideas about how to improve some of these approaches which I’ll gladly talk about to anyone who wants to listen, but I don’t know how to overcome the fundamental problems at the start of this section. And nor does anyone else, which is why practically everyone else uses rasters.
Boring technical details about writing systems
Congratulations on making it through the whistle-stop tour of font generation models; your prize is a bunch of geeky details about writing systems and machine learning models, but which, I believe, explain the contradiction between why there are production-ready Chinese font models and yet all the Latin font models are a bit of joke.
There are some obvious reasons why this is, and let’s get them out of the way first. It comes down to those competing objectives again. Chinese font design is a lot more complex simply because of the glyphset size, but in other ways it’s a lot simpler. You don’t have to deal with spacing, kerning, vertical metrics, ascenders, descenders, width variation, ligatures, or features. The drawing is the work. If you can get the drawing done, you’ve got a font. And so even if you managed to perfectly apply a model designed for CJK glyph generation to a Latin glyphset, you still wouldn’t have a working font. The funny shapes are just a tiny part of the work.
But it turns out you can’t perfectly apply a Chinese model to Latin glyphs. I tried a little experiment (nb: this was not a “little” experiment; it was a freakin’ huge experiment): I took the model described by the “Beyond Patches” paper, and I trained it on the Google Fonts dataset. It completely failed. Beyond Patches has two components - you have to train a “tokenizer” before you can train a “generator”, and I couldn’t get past stage one. The tokenizer underwent total codebook collapse, which means that it learnt to predict one sequence for every single glyph, and that sequence was “just make everything white”. Every glyph image became a blank glyph. Why is that?
Well, let’s compare an average Chinese glyph with an average Latin glyph, at the kind of scales that ML models see them. (Typically 64x64 pixels, or 128x128 pixels if you’re very lucky - 128x128 is four times more pixels than 64x64, making your model four times bigger. Another doubling gets you to 16 times bigger, and your model gets too huge to train.) Here are the letters “瑽” and “e” respectively, zoomed up a little.
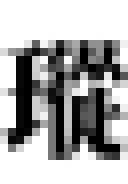
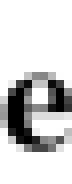
Notice that the Chinese glyph is considerably more dense. It’s close enough to 50% grey - or to put it another way, an equal balance of white and black pixels. In contrast, the Latin glyph has much more white pixels.
In fact, in reality, it’s worse than that. ML models require all images to be the same size, and while Chinese glyphs are all designed to fill an equal-sized em-square (no problem!), Latin glyphs vary considerably in width. The glyph image for the letter “e” that you feed into an ML model must be width enough to also accomodate the letter “m” or “W” or whatever. Worse than that, you also have to accomodate possible ascenders, descenders, glyphs with accents, and so on - things which Chinese doesn’t have to deal with at all. So in short you need to be able to put your widest, tallest and deepest glyphs within the same glyph box. What that means is that the actual glyph image you use for the “e”, which was pretty much made of majority white pixels already, has to be further padded by a lot of white space. (“i” is going to be even worse. “.” is going to be a small island in an ocean.) Let’s estimate conservatively that the glyph image for the average Latin glyph is about 80% white pixels.
ML models love balanced class problems. If an image is close to 50% white pixels and 50% black pixels, you genuinely can’t guess which is which and you actually have to work out which pixels should be white and which should be black. But when presented with an imbalanced class problem, models get horribly lazy. If a model learns that it can get 80% of the answer right just by guessing a white pixel every single time, that’s exactly what it’s gonna do, and it’s incredibly difficult to disabuse it of the notion that this is an adequate solution to the task. Hey, if I got an 80% score on a test without trying, that would also be good enough for me.
Once you’ve got past that problem, there is another problem which is specific to style transfer - generating new glyphs in the same style as glyphs in an existing font. The challenge is the way that glyphs vary between styles is different for Chinese glyphs and for Latin glyphs. Chinese glyph variations are actually fairly limited in their stylistic capacity. Sure, they will look very different in terms of ductus, terminals, brush stroke and so on. But fundamentally CJK characters will have pretty much the same structure across fonts. They all fill the same em-square, a character is fairly well-defined in terms of its radicals and its composition, meaning that the glyph skeleton is the same, which means that the different components of the design will always be in roughly the same place; comparing the same glyph across Chinese fonts is like looking at the same person wearing different clothes.
But the same Latin letter “a” might vary wildly by width, height, construction (double story/single story), and so on. The skeletons of two different “a” glyphs between fonts can be not just different but completely different. Comparing the same glyph across Latin fonts is like looking at bunch of different people with different body shapes. This means that different styles of the letter “a” may end up in different regions of the font design universe. Frankly it’s only because we’re used to reading Latin text that we even consider a double-storey “a” and a single-storey “a” to be the same letter - looking at these two designs as an alien from Mars, you would not believe it to be true. And as a result of that, if you’re trying to organise font glyphs into regions of the design universe, some styles of the letter “a” may end up closer to the “c” or “e” region than they do to other styles of the letter “a”. This would mean it’s not possible to navigate between them, which a style transfer model needs to do.
There are ways around this, of course, but the point here is to show that if you find an advanced glyph model coming out Chinese research you can’t just pick it up and apply it to Latin design.
Conclusions: Where are we heading?
There are a lot of options and a lot of research out there when it comes to automating type design. But the economic and social factors mean that most of that research is happening for Chinese fonts. It’s not necessarily transferable. But at the same time it’s not necessarily not transferable either. There are certainly emerging models such as UT-Design and FontDiffuser which are already proven to work on Latin fonts. Of course, they just get you the drawings - they don’t do vectorization, spacing or kerning. These are the real hard parts of Latin font design, and I don’t see much going on there at the moment.
My guess is that we’re still three or four years away from an AI which can generate fonts. But then, I would say that, wouldn’t I? I’m not Chinese.